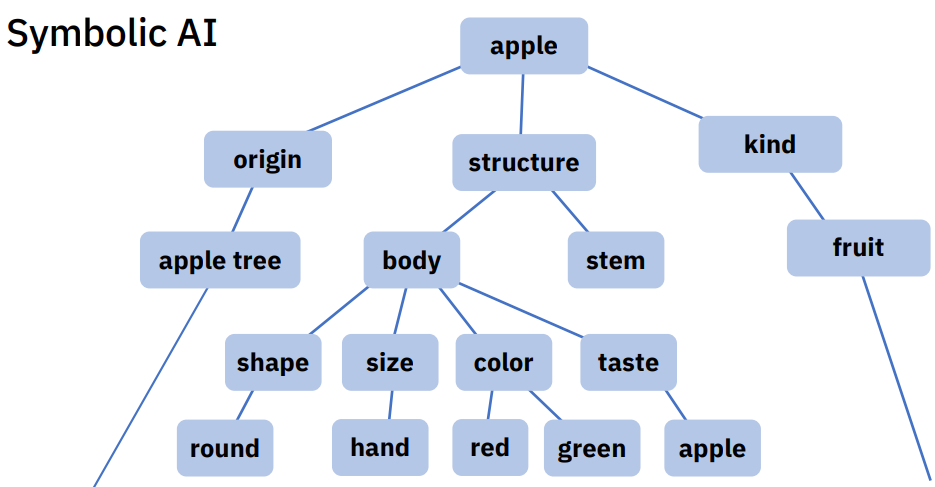
Today AI is emphasized by Convolutional and Adversarial neural networks. One of the most robust and popular today are the GPT tools developed by OpenAI. While neural network approaches can build relationships between concepts or words they don’t actually give meaning or understand the concept or words, they just develop a statistical relationship between words. Another problem, as discussed before, is that Neural Networks take a lot of examples to learn. Because neural networks build statistical maps of words and don’t really understand concepts they can oftentimes reach the uncanny valley and even with the GPT tools the outputs are not always coherent. With a symbolic approach, the machine can learn from one example and it actually develops or understands the real meaning of ideas or words!
However, the symbolic approach was actually the first approach AI scientists pursued. One of the approaches of Symbolic AI is object-oriented programming OOP. With OOP one can define classes with properties and functions. OOP allows for hierarchies where inheritance can be implemented. This allows for instance a class defined as an Animal that has the properties and functions that almost all animals have. Now if you want to define a “Cat” class you can allow it to inherit from the Animal Class where it will have all the properties and functions of the Animal Class. Not only that but OOP allows for functions to be customized for a particular implementation. So the “Cat” class can use some of the functions of the “Animal” class but also override other functions with its own customize function. A problem with OOP is that it is a language and requires a compiler or interpreter to apply its rules.
With symbolic AI one can define or describe concepts or words in various attributes or classifications that can even represent states. The problem however is that using OOP may not be the best approach, but an object-oriented data model (OODM) might be a better choice. With an OODM there is no re-compiling for changes in data structures, it all happens in real-time!
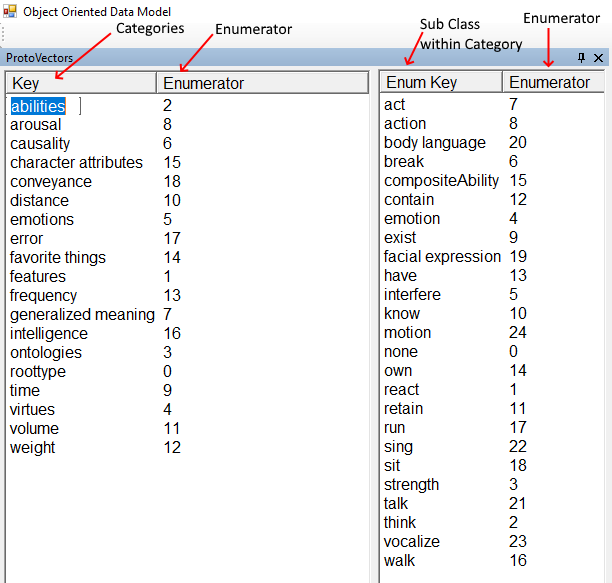
The image above depicts an approach of grouping concepts or classes and having subclasses within each category, or what we call a “ProtoVector”. This approach is not new. All concepts and objects can be described in a general way and if a concept or object has some attribute that isn’t a part of the database of concepts new categories can be added. In fact, the machine can be told to add a new concept or if it deems it appropriate create a new category. Each category and its subclasses are enumerated. The software manages the enumeration so all that needs to be done is to add a category or subclass. However this is not the crux of OODM, but only an attribute to be used by OODM.
An OODM solution must be able to apply OO concepts to establish relationships between concepts.
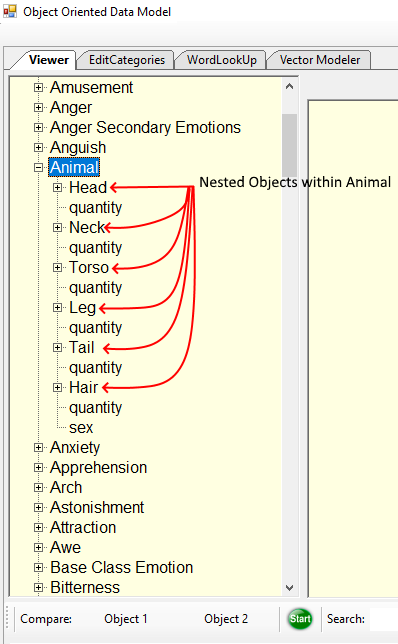
Above is an image of the data model editor and viewer where OODM objects or concepts are listed. The model is composed of a class object called a “RootDescriptor” which is composed of “MicroDescriptors” and RootDescriptors. The RootDescriptor “Animal” is highlighted in the image above and expanded. The Animal descriptor is composed of RootDescriptors Head, Neck, Torso, Leg, Tail, and Hair.
RootDescriptors always represent complex concepts or objects where as MicroDescriptors are always one of the ProtoVectors that can be assigned other types of data such as audio or video data, vectors, library functions or processes, pretty much any kind of data can be associated to a MicroDescriptor.
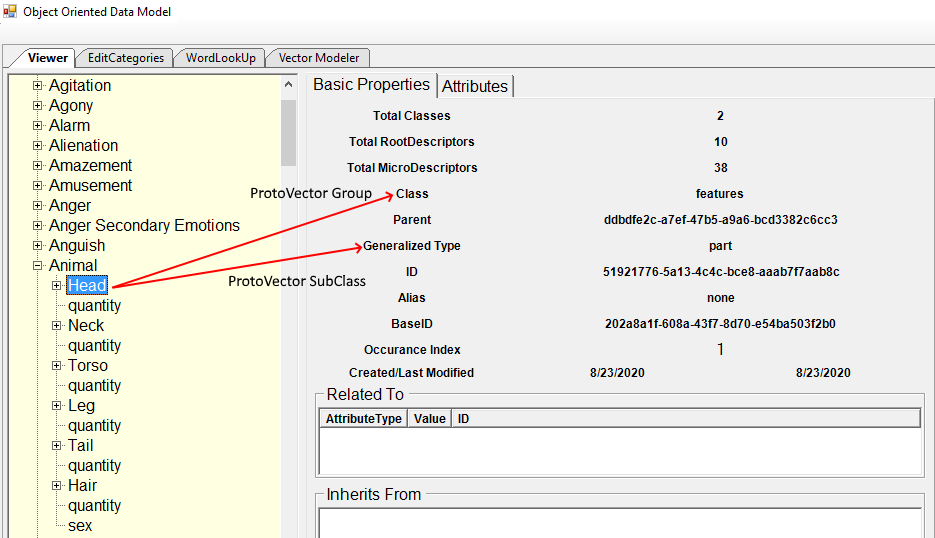
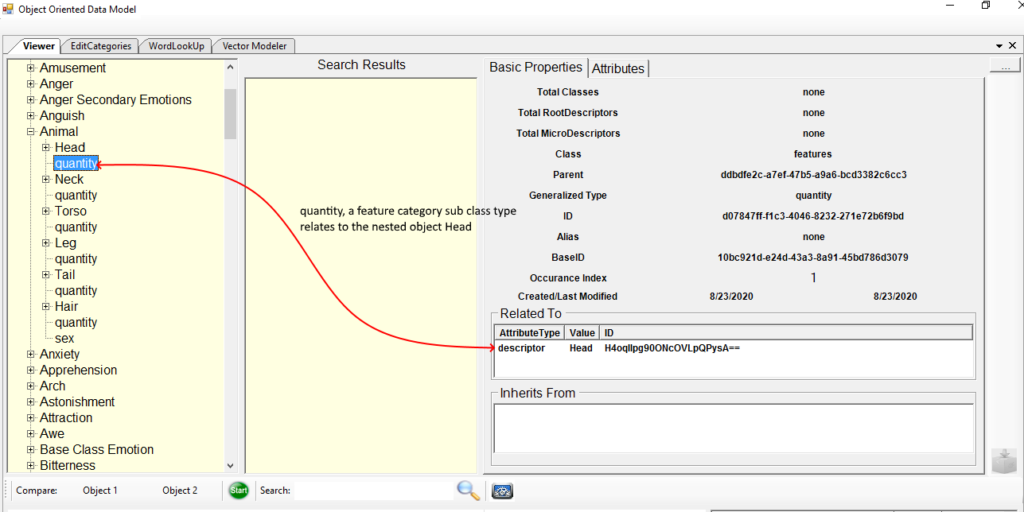
The image above shows the RootDescriptor “Head” for the parent RootDescriptor “Animal” where the class is the Group Protovector “features” and the Generalized Type is the SubClass ProtoVector “part”. A head is a part of an Animal.
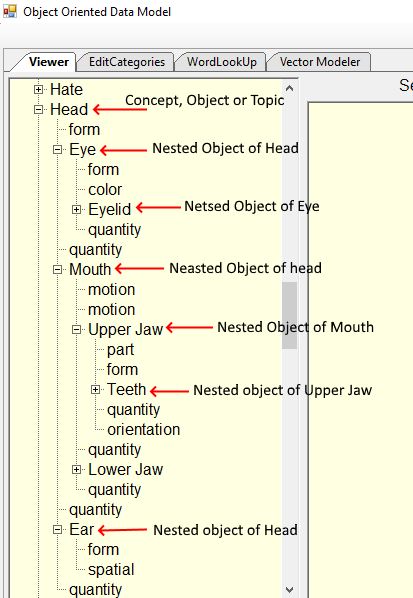
Also, note that the RootDescriptor for Animal is comprised of many RootDescriptors, there is no limit to how deeply nested a RootDescriptor can be as the example for the RootDescriptor for “Head” is shown above.
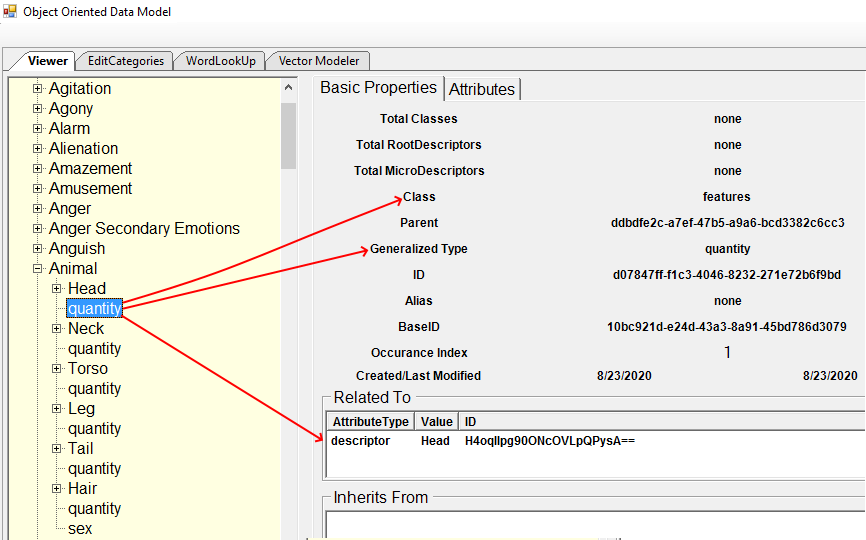
The image above shows the MicroDescriptor “quantity” highlighted. The class is the ProtoVector “features” and the Generalized Type is the SubClass ProtoVector “quantity”. An Animal has one head:

So this is what comprises the OODM: RootDescriptors and MicroDescriptors, however, there is also inheritance:
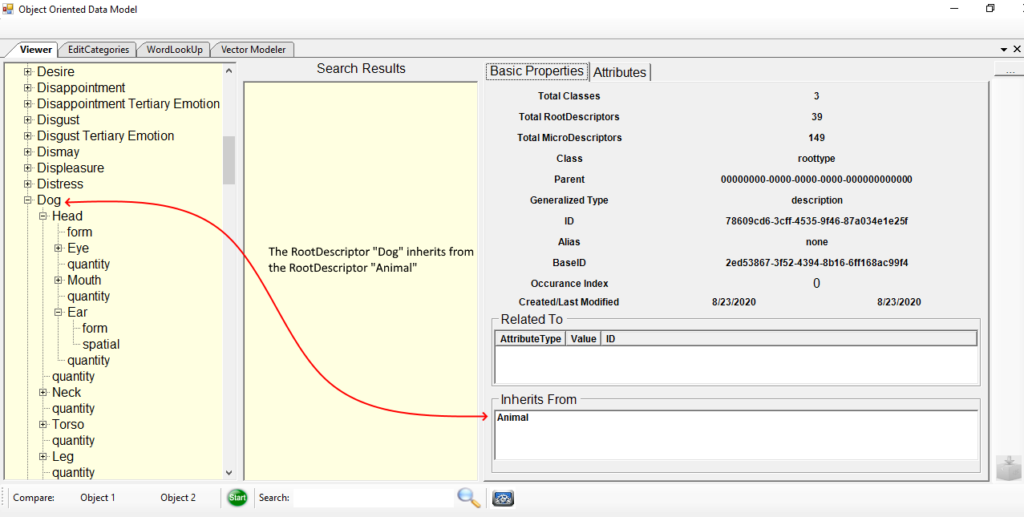
The image above has Dog expanded and depicts in the Basic Attributes Panel that it Inherits from Animal.
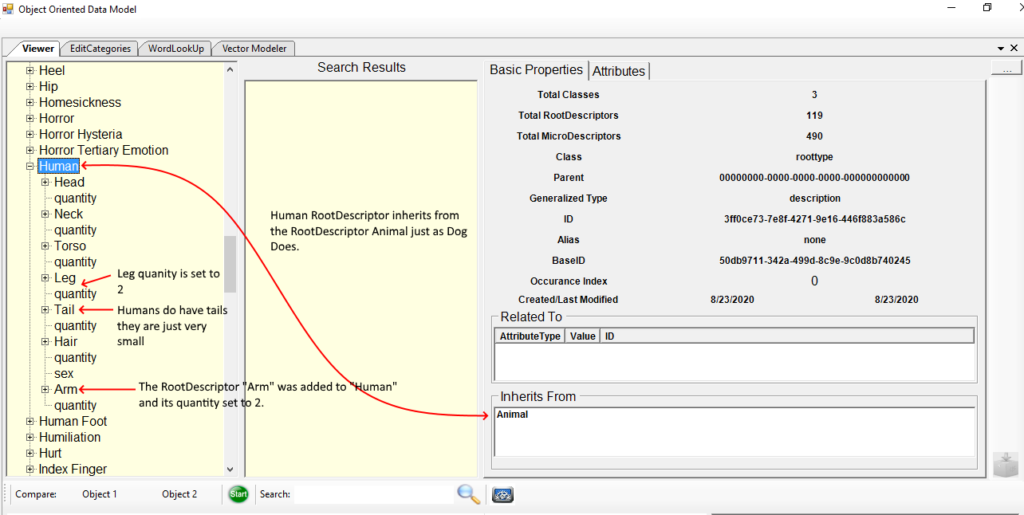
Here is another example of inheritance from Animal. Human inherits from Animal but it changes the quantity of Legs to 2 and adds Arms. So OODM allows one to change attributes and add new Descriptors to a RootDescriptor that inherits from another RootDescriptor.
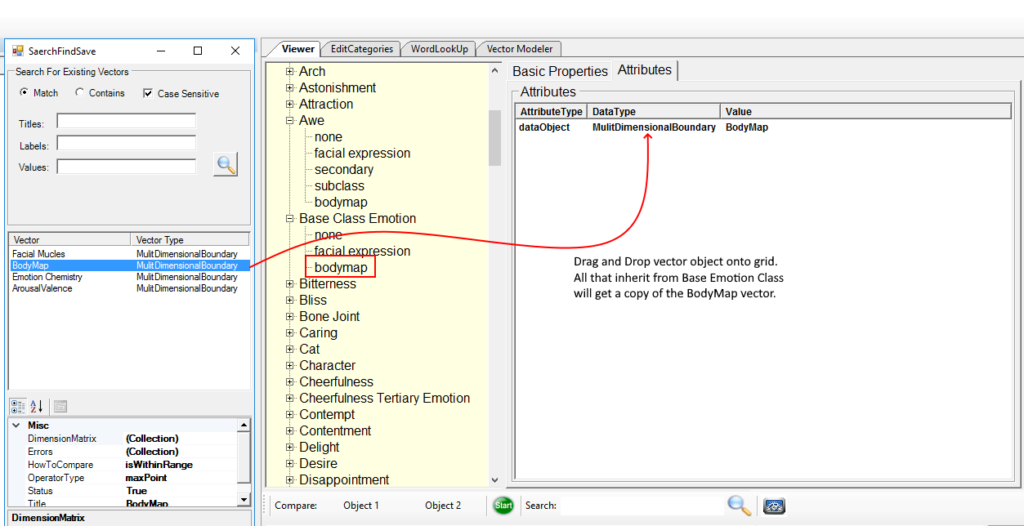
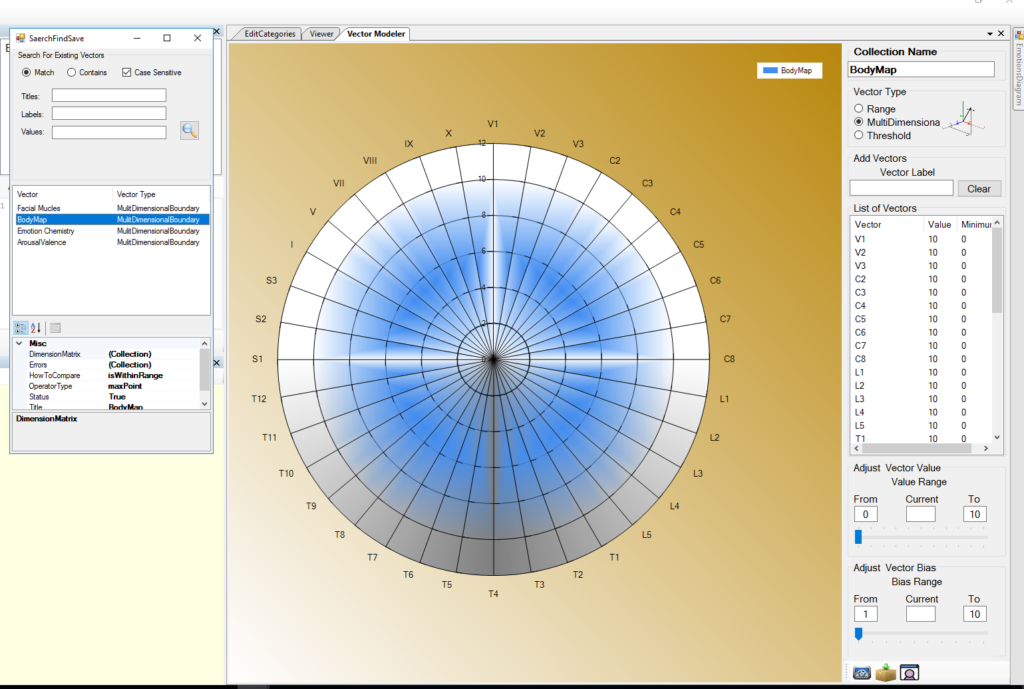
This particular implementation of OODM uses fairly simple OOP classes and is stored using an Object-Oriented Database or NoSQL database. But its simplicity is its strength and while the basic OOP class is simple RootDescriptors can get very complex and do not have any limit in describing concepts or objects. This approach effectively gives words meaning. Because of the generalization from the ProtoVectors this approach can compare concepts and detect their similarities and differences no matter if there are disparities between the words or ideas. Also, because any kind of data can be associated with the MicroDescriptors this approach of Symbolic AI doesn’t suffer from the brittleness of past approaches that would have to code new rules for nuances or differences in new concepts that could be introduced.